
Data Pipeline for Near Real Time Analytics at Large Scale – Part 1
Introduction
Before I start with what a Data Pipeline means and why near Real Time Analytics is important, I want to touch upon some very interesting things from a study done by Gartner research. IoT (Internet of Things) has seen an explosion in the number of connected devices in the past three years, and as per their research we will have 25 billion “things” connected to the internet by 2021. There is an exponential expansion in this domain and manufacturing, healthcare and insurance companies are positioned to be benefited most by this growth.
With this expansion a lot of data is going to be generated by devices that are connected to the internet and some real time decisions need to be made. Not only IoT, a lot of real time decisions need to be made for user personalization and behavioural targeting of the user. It’s impossible to imagine payments system without fraud detection in today’s world. As an organization there is an immense need of data pipeline that can track, collect, consume and arrange this data in a way that, the organization can slice and dice to drive some value out of it in near real time.
In real world data is produced from many sources and in multiple formats and it is very important for any organization to process it in a way to make some sense out of it. Data Pipeline is step by step setup of processes for collecting,streaming, transforming and storing data that can be used for analysis. I will be briefly discussing the bird’s eye view of various components of any data pipeline in this post.
Components of Data Pipeline
Before I explain various components of data pipeline, here is a diagrammatic representation of all services in any data pipeline
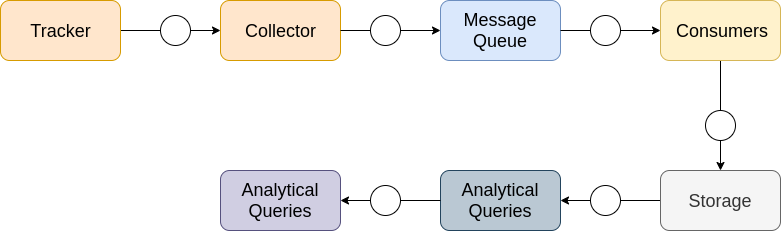
Let’s talk about all components one by one briefly.
Data Trackers: Data trackers fire events whenever an event on a website or application takes place. This collection is done by making GET/POST/TCP requests to your collector endpoint. Depending upon the criticality of data you can batch events in a single call or push the event as soon as it happens. Data trackers should be implemented in a lightweight manner and shouldn’t affect the performance of the application where the tracker is getting integrated.
Data Collection Endpoint: The role of data collection endpoint is very simple, it provides a set of API where all clients can send their data and this endpoint does some lightweight validation and writes it to some intermediate messaging layer. If you need some operations that do some kind of data enrichment, don’t try to do it on this Endpoint. The role of collection endpoint should be to capture as many data points it can with minimal resource usage. Based on your use case these endpoints can be REST, Web Socket or some RPC framework. Keep in mind that these endpoints need to be stateless in nature and do not run in the same environment as your critical endpoints which are transactional in nature. This will allow you to run multiple instances, and you can essentially put them in geographically different locations to accept requests from across the globe with minimal latency. If you are running in cloud environment try to use auto scaling to ensure no data point is dropped.
Messaging Queue: The role of messaging is to efficiently stream data in a highly scalable and durable manner. There are a lot of implementations that can solve the purpose. To name a few Apache Kafka, Pulsar, RabbitMQ are the ones getting a lot of traction. I personally prefer Kafka, because its very easy to set up and unarguably the backbone of any data pipeline built using open source tools. Kafka is widely adopted by the industry and is linearly scalable, and provide good durability guarantees, plus it can run efficiently on commodity hardware and has a great community support. Kafka also provides some interesting features like Kafka Stream aggregations and Kafka SQL to make your life easy to apply analytics on streaming data in real time. Some of the managed services to do this are AWS Kinesis, Google PubSub
Data Processing Consumer: This is the place where you would essentially do any kind of data processing or data enrichment. The consumers should be designed by keeping one important thing in mind i.e to keep them stateless and this consumer should have only one single responsibility. If your data enrichment and data processing requires multiple steps needs to be performed, you should consider using multiple consumers and use topics/queues for intermediate storage of data with low retention values. Think of it as an assembly line where each consumer is doing only one operation and these operations are sequential in nature most of the times(can be parallel in some cases). Based on the use case consumers can perform computations over bounded and unbounded data streams.
Data Storage Mechanism and Query: This will be the heart of your platform, if this doesn’t work all the work done above will be a waste of effort. Based on the use case you can have one or more types of storage mechanisms. Widely you’ll have to think of two types of storage Hot Store or Cold Store. These are generic terms to differentiate between your actively queried data(Hot Store) and data that you will not query very often but might need in the future for generating reports out of it. Usually you will choose your hot and cold data store based on what kind of use cases you are trying to cater to. If you are looking for managed services for storing data, you can use Redshift, Bigquery, EMR, Athena etc.
Things to keep in mind while implementing a Data Pipeline
- Data Retention and data cleanup strategy
- Stateless micro services from data collection to data ingestion
- Services should scale out and scale in based on traffic
- Collector service should have a low latency. Geographically distribute it to prevent loss or event.
- Implement a dead letter queue for messages that gets failed while collection or enrichment
I hope all of you got to know something about data pipelines. Setting a data pipeline is simple provided you keep in mind the scalability and fault tolerance. With this post I tried to scratch the surface of building a data pipeline, in next post I’ll walk you through an implementation of a data pipeline to solve user segmentation and targeting problem at Infoedge Hackathon 2019.
About The Author
Amandeep Singh
Technology Craftsman. Data Enthusiast. Super Lazy. Cricket Buff.